DataCube
Технология формирования единой модели данных, собранных из различных источников и СУБД с целью ее обработки и визуализации
Описание
Современное информационное пространство - это хаос с большим количеством разнородных источников структурированной и неструктурированной информации. Открытые данные, файлы, корпоративные хранилища, онлайн-сервисы, разнородные СУБД (SQL и noSQL) - все эти источники хранят разную информацию в разных форматах и работают по разным протоколам.
Технология DataCube представляет собой комплекс встраиваемых клиент-серверных компонентов, который обеспечит разрабатываемое ПО возможностью интегрировать разнородные источники в единую модель данных в виде OLAP куба с определенной структурой и унифицированным языком запросов.
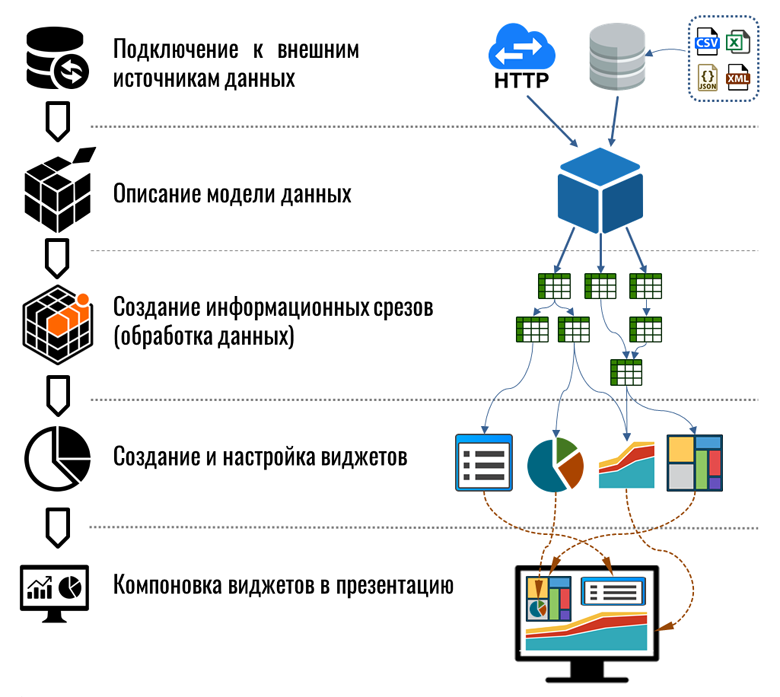
Общая схема процесса интеграции выглядит следующим образом:
Куб, срез, измерение
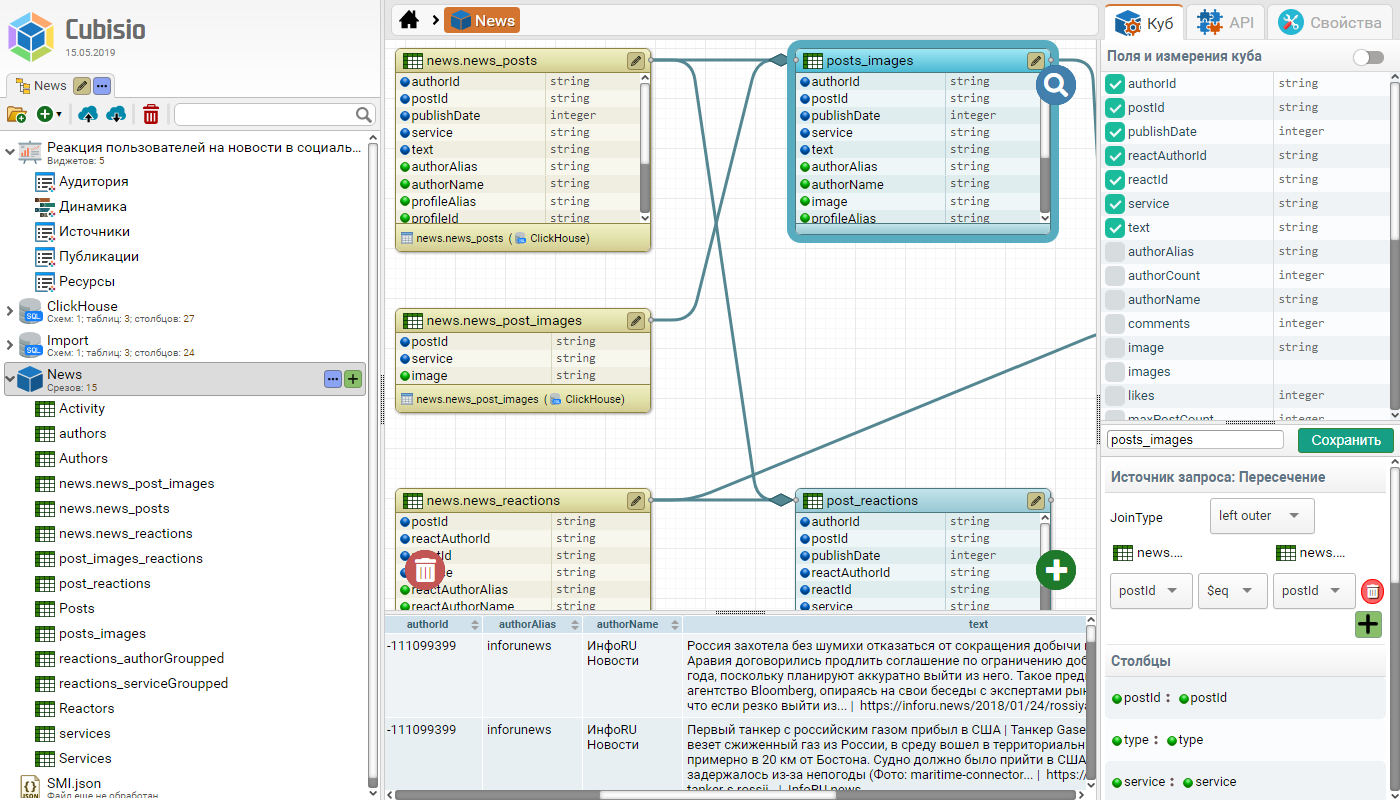
Основная задача DataCube – имея наборы несвязанных данных, включая разнородные внешние базы данных и файлы, сформировать многомерную модель из связанных между собой элементов исходных данных и результатов их аналитической обработки.
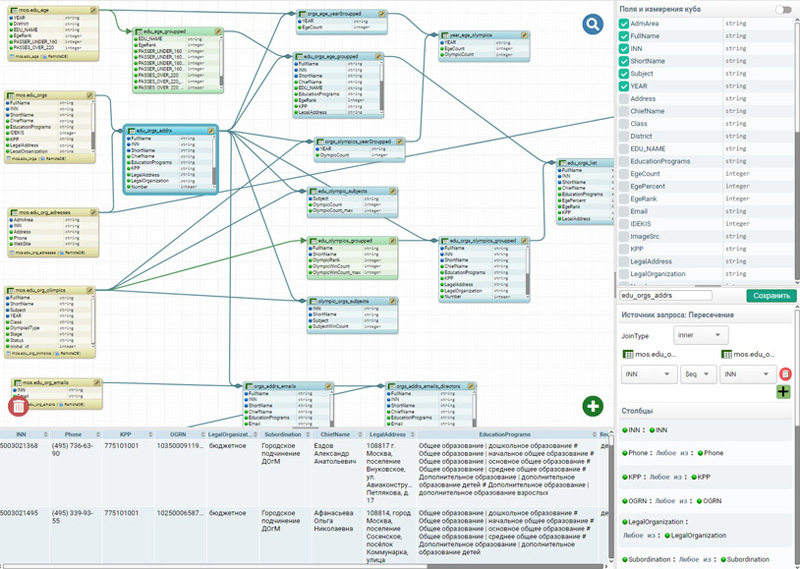
В DataCube такая многомерная модель данных называется "Куб" и буквально представляет собой наборы данных, называемых "Срез", связанных между собой общими полями, называемыми "Измерения", которые используются для фильтрации и связывания срезов между собой.
С помощью цепочек срезов разработчик может извлекать из куба интересующие его информационные аспекты в виде таблиц с данными и последовательно их преобразовывать, добавляя в каждый последующий срез новые условия вычисления.
В момент работы все аналитические запросы к кубу проходят через ряд преобразований и в конечном итоге выполняются непосредственно на стороне СУБД. Если какая-то из подключенных СУБД не поддерживает требуемых функций, куб выполняет их самостоятельно.
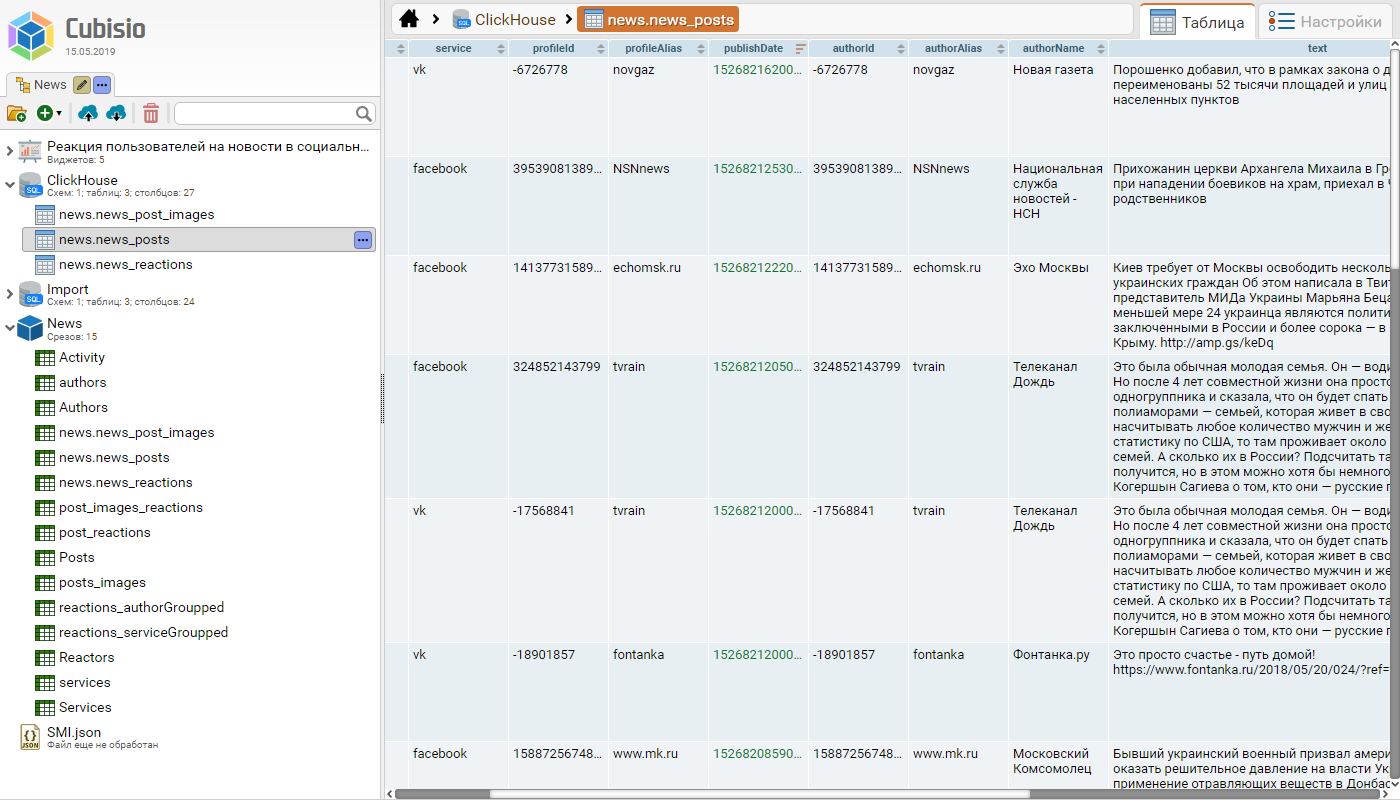
Источники данных
В DataCube реализован механизм сопряжения внешних источников, который позволяет согласовать форматы и языки запросов, а также обеспечивает контроль целостности данных. Для этого мы разработали универсальный язык запросов, подходящий как для представления виртуальной модели данных куба, так и для работы с условно-произвольными хранилищами засчет трансляции запроса к нужному формату и языку.
В настоящий момент DataCube поддерживает три основных механизма взаимодействия с источниками:
Подключение к внешним СУБД
Одна из ключевых возможностей DataCube – взаимодействие со сторонними СУБД «на лету» без необходимости копирования данных в свои внутренние структуры. Этот подход эффективен при работе с хранилищами, где данные периодически обновляются.
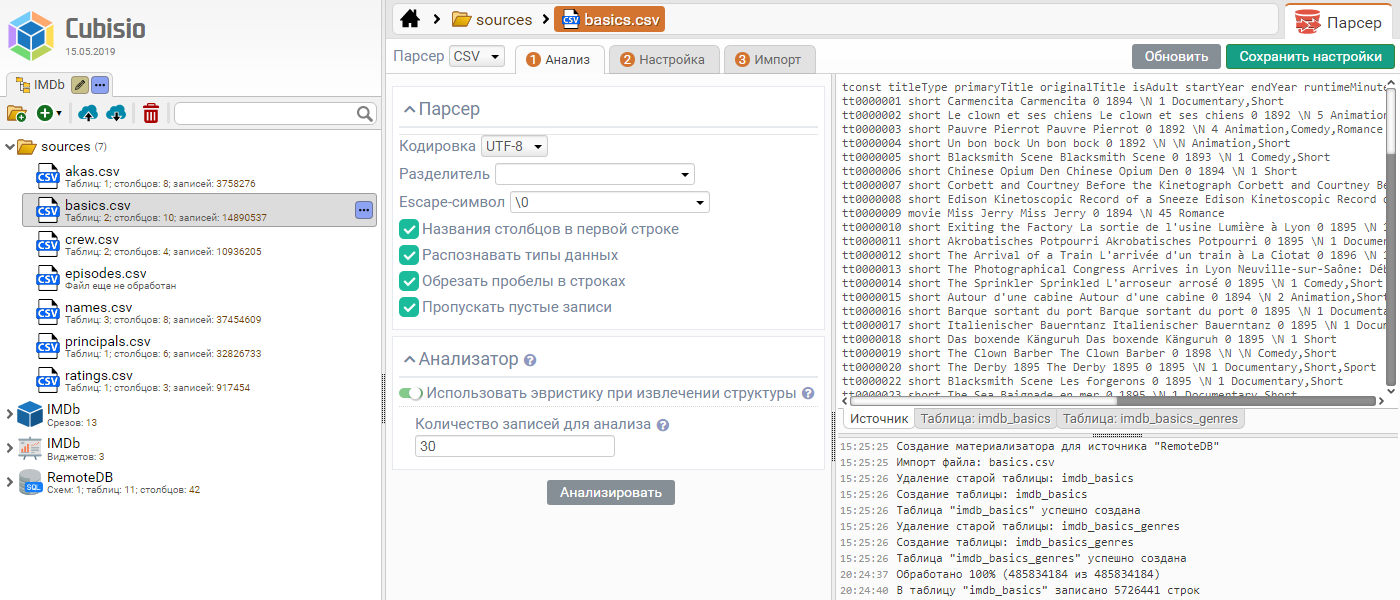
Импорт данных из файлов
Импорт данных во внутреннюю или подключенную СУБД осуществляется при помощи парсера, функционирующего на основе подключаемых грамматик. Парсер DataCube поддерживает большинство популярных форматов файлов – CSV, JSON, Excel, XML, а также может быть настроен разработчиком на произвольный текстовый файл путем описания его грамматики. Импорт осуществляется в два этапа – подготовка и непосредственно импорт. На этапе подготовки пользователь имеет возможность подготовить сторонние данные к закрузке в базу – разбить по таблицам, настроить столбцы и выполнить предварительные преобразования.
Подключение к внешним HTTP-сервисам
В DataCube реализован механизм взаимодействия с любыми удаленными веб-сервисами по HTTP протоколу с возможностью управления параметри��ацией запросов. Ответ от веб-сервиса обрабатывается парсером, и его структура также может быть предварительно подготовлена для дальнейшего использования.